 с SEO-целями")
Еще одна отличная практическая статья — гостевая, для моего блога от Dr.Max (автора учебника «SEO-Монстр 2020» и других).
Другие гостевые статьи Dr.Max можно прочитать тут.
Интервью с ним можно почитать у меня в блоге тут. Рекомендую, увлекательно и полезно.
 с SEO-целями - гостевая статья от Dr Max")
Анализ журналов доступа к сайту с точки зрения SEO
Анализ лог файлов сайта (или по-другому – журналов доступа) с точки зрения SEO является крайне полезным занятием, дополняющим технический аудит сайта и предоставляющий массу полезных сведений, необходимых чтобы понять не только техническое состояние сайта, но и отношение поисковых систем (далее ПС) к нему.
Перечень решаемых проблем при анализе журналов доступа крайне обширен.
С его помощью можно:
• Определить URL, сканируемые ботами ПС. Тем самым можно понять, какие страницы сайта сканируются ботами, и как часто это происходит.
• Для того же Google можем понять, какие именно боты чаще сканируют сайт (мобильные, десктопные и т.д.). Кроме того можем найти ошибки, например, присущие мобильной версии сайта, при их отсутствии в десктопной. Ни один эмулятор сканирования сайта (тот же пресловутый Scream Frog SEO Spider) вам это не покажет.
• Узнать частоту сканирования тем или иным ботом. Можно определить какие страницы боты любят больше, какие меньше и сколько страниц в день всего сканирует тот или иной паук. Тем самым мы наглядно видим не только бюджет сканирования, но и его динамику, в зависимости от действий, предпринимаемых при продвижении сайта.
• Можем найти ошибки на сайте. Анализ кодов ответов страниц достоверно покажет битые страницы, ссылки на сайте. Так мы можем посмотреть на сайт глазами самих ботов.
• Можем проанализировать все 3XX перенаправления. Этот анализ позволит избавится от ненужных перенаправлений, оставшихся, например, от смены структуры URL. В свою очередь это поможет сэкономить бюджет сканирования и повысить доверие ПС к сайту. При этом 3XX переадресации могут заметно отличаться от представленных в браузере или при эмуляции сканирования, например Scream Frog SEO Spider.
• Устраняя найденные ошибки – улучшаем бюджет сканирования сайта.
• Можем найти избыточно большие и/или излишне медленные страницы сайта. Как известно, скорость доступа к сайту является одним из факторов ранжирования. Устранив проблемы с медленными или излишне громоздкими страницами, мы улучшаем ранжирование сайта.
• Определить страницы- потеряшки. Если сопоставить страницы, которые боты отсканировали с текущей структурой сайта, то легко найти страницы – сироты, т.е. те страницы сайта, которые заведомо никогда не будут отсканированы, не попадут в выдачу органики ПС.
Итак, нет никаких причин, чтобы не заняться анализом журнала доступа.
Эта абсолютно бесплатная и простая процедура иногда может резко поднять качество сайта, улучшить его ранжирование, и помочь вам в достижении ТОПов выдачи.
Прежде всего, нам нужны log-файлы за достаточно длительный период, например две недели. Чем больше изучаемый сайт, тем за более длительный срок нужны log-файлы.
На отдельных хостингах журналы доступа генерируются по умолчанию, на других их нужно включать принудительно.
Например, так это выглядит у Beget:
 у Beget")
Включив логирование доступа к сайту, получаем ежедневно по лог-файлу, которые скачиваем и сохраняем к себе на компьютер. У иных хостеров логирование может настраиваться по иному. Читайте хелпы своих хостеров.
Сырой log-файл представляет собой мешанину упорядоченных данных, которые можно, конечно проанализировать в том же Excel. Вот так выглядит кусок журнала:

Поскольку проблема анализа log-файлов встала перед вебмастерами очень давно, за десятилетия было написано немало программ. Вы можете воспользоваться любыми из платных или бесплатных вариантов, например: Web Log Storming, Sawmill, Web Log Explorer, WebLog Expert, Log Analyzer: Trends, Log Viewer Plus и т.д. и т.п. Программ десятки, если не сотни, причем есть как десктопные, так и серверные варианты.
Скачать его можно здесь: https://www.screamingfrog.co.uk/log-file-analyser/
Ключик можно или купить или, если позволяет совесть, легко найти в Интернете.
Создаем новый проект и добавляем всех необходимых для анализа ботов:

Если сайт очень большой, и вы хотите кушать медведя по кускам – то можно анализировать отдельные составляющие сайта.

Импортировав для примера логи за 5 дней, получаем следующую картину:

К сожалению, 5 дней – это очень мало и не дает полную картину творящегося с сайтом, но для образовательных целей – этого достаточно.
Screaming Frog Log File Analyzer позволяет подгрузить структуру сайта, собранную в Screaming Frog SEO Spider, что мы немедленно и сделаем. Теперь у нас есть урлы, которые попали в логи и урлы, собранные спайдером.
Давайте быстро разберемся с основными функциями Log File Analyzer:

1 – Выбор бота ПС из набора
2 – Выбор периода анализа
3 – Панель инструментов.
4 – Выбор из наборов данных:
Log File – данные из журналов доступа
Matched witch URL data – URL имеющиеся и в log файле и в загруженной структуре из SEO Spider
Not in Url Data – отсутствующие в загруженной структуре из SEO Spider
Not in Log File – отсутствующие URL в log файле
5 – Выбор URL для анализа
6 — Закладка полных данных по выбранному URL
Оперируя этими инструментами можно найти значительное число неполадок и нарушений, а самое главное – путей оптимизации сайта.
Ну вот, например, поиск страниц, которые нет нужды обходить ботам, а они это проделывают, тратя тем самым бюджет сканирования.
Используем инструмент URLs(1), закладку Not in Url Data (2) и сортируем По столбцу Last Response Code.
Что интересно, о том что спайдер Гугла (на скрине стоит All Bots – но нужно выставить Google Bots) ходит по «закрытым» URL мы можем узнать, только анализируя логи.

Как мы видим, Google зашел на https://drmax.su/page/2 , что нам не нужно, тем самым потратив бюджет сканирования на бесполезную страницу, которая закрыта в robots.txt в секции Google (1) директивой Disallow: /page/
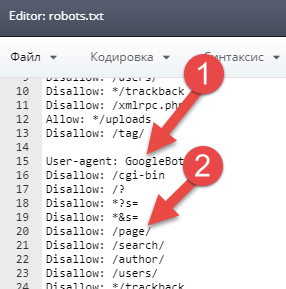
Мы прекрасно знаем, что с точки зрения Google (но не Яндекса), robots.txt не предназначен для запрета индексирования (и попадания в выдачу) любого контента сайта.
https://support.google.com/webmasters/answer/6062608?hl=ru

Значит, на странице https://drmax.su/page/2 неправильно прописан метатег robots. Смотрим исходный код страницы:

Видим, что метатега robots нет и в помине, хотя есть canonical на главную. Однако, canonical – это всего лишь рекомендация (точно так же как и с robots.txt), а не запрет индексации страниц и при наличии, например, внешних ссылок на страницу https://drmax.su/page/2 — она с большой степенью вероятности будет проиндексирована. Поэтому, необходимо прописать метатег robots и указать в нем noindex для этой страницы.
Анализируя подобным образом данные, предоставленные программой. мы находим все узкие места.
Желательно, предварительно ознакомиться с книгой «Аудит сайта своими руками», чтобы понять на что стоит смотреть и что является ошибкой.
Пример попроще – ищем самые «тяжелые» страницы.

Для этого просто сортируем данные по столбцу «Average Bytes». Соответственно, отсортированные файлы нужно будет изучить на предмет уменьшения их «веса».
Перейдя в закладку «Response Code» (1) мы можем просмотреть все ошибки сайта (2), при этом опять можно отбирать источники данных (3)

Например, вот такая есть ошибка у меня на сайте, которая выявляется только анализом log-файла.
Открываем закладку «Response Code» (1), ошибки 4xx (2), данные имеющиеся только в лог-файле (3) для мобильного бота Гугла (4).
Здесь мы видим, что на страницах (6):
https://drmax.su/book-audit.html
https://drmax.su/category/rukovodstva
https://drmax.su/download
Есть некое изображение
https://drmax.su/wp-content/uploads/2018/06/cover2@2x.png
ссылка на которое появляется только в мобильной версии сайта (4) и оно «битое».
Причем изображение https://drmax.su/wp-content/uploads/2018/06/cover2.png — существует
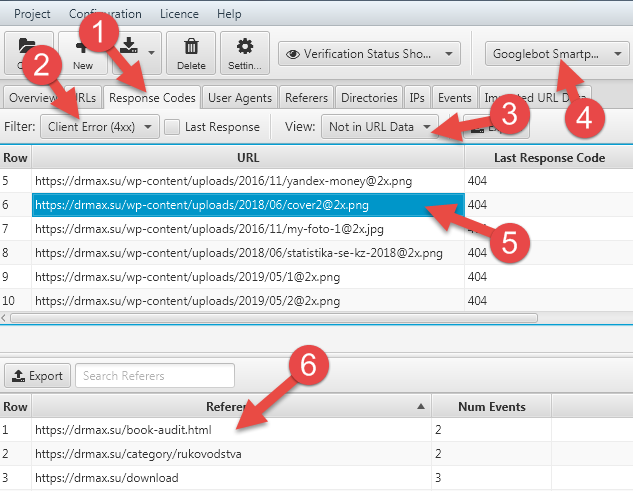
Эта ошибка в моем шаблоне возникла после экспериментов с Retina версией изображений – т.е. с изображениями повышенной плотности для разных там Apple и иных устройств с огромными экранами и высокой плотностью точек на них. Теперь куча бюджета сканирования тратятся на файлы, которых у меня заведомо нет.
Ошибка известна, требует исправления.
Возможности программы поистине безграничны.
Например, на больших сайтах вы можете использовать в качестве пары набора данных Sitemap и лог-фал, собранный за 2-3 месяца. Потом можно посмотреть, какие страницы из Sitemap не индексируются ботами (переключатель в Not in Log File).
Потом вы должны проанализировать эти найденные страницы и понять, что тут происходит – то ли разрушена структура ссылок (робот просто не доходит до этих страниц – но это редко, см далее…), либо эти страницы являются Thin Content и требуют радикального к себе отношения.
См статью «Аудит контента и обрезка ядовитого содержания».
Роботы иногда попадают в «ловушки», когда крупные сайты имеют развитую систему фильтров и крайне непродуманную систему навигации. Тогда бюджет сканирования может быть исчерпан, когда робот запутается в миллионах страницах с генерируемыми URL-параметрами. Все это тоже отслеживается анализом лог-файла за длительный период.
Рекомендую вам потратить 2-3 дня на изучение программы и собственного сайта и вы обнаружите удивительно глупые ошибки, исправив которые, вы несомненно повысите качество сайта и поможете продвинуть его в ТОП.
Автор статьи — Dr.Max.
Напоминаю, что 4 дня — с 16 по 19 июля 2019 года действует очень большая скидка 50% на лучший SEO-учебник от автора этой статьи.
Смотрите содержание практического руководства «SEO-Монстр 2020» на 700 страниц здесь.
Берите прямо сейчас! Этот учебник должен прочитать каждый, у кого есть сайт или кто продвигает любой сайт.

В SEO 13 лет, Опыт работы с буржуями – 7 лет. Крупнейший буржуйский клиент – с годовым оборотом интернет портала в $800.000.000 в год. Работа в 98% под Гугл.
Хотите больше знать об авторе? Прочитайте у меня в блоге интервью с Dr.Max — о SEO и о жизни.
Можете почитать, например, его ответы в экспертных опросах у меня на сайте:
— Опрос №2 «Разница в продвижении под Яндекс и Гугл»
— Опрос №3. «Фильтры поисковых систем в 2018 году»
и ряд его гостевых статей у меня в блоге:
— «Показатель отказов: исследование, сегментация и оптимизация метрики Bounce Rate»
— »Эволюция SEO текстов к 2018 году»
Как купить учебник «SEO-Монстр 2020» со скидкой 50%:
Вместо 95$ (текущая стоимость учебника на сайте Dr.Max), сейчас здесь у меня его можно приобрести со СКИДКОЙ 48 долларов за
Скидка действует только с 16 по 19 июля 2019 года.
Оплата разными вариантами.
Высылается сразу, на автомате.
Берите, и сразу же приступайте к чтению и внедрению написанного!
Сюда входит поддержка автора (можно задавать ему вопросы). Вы становитесь обычным покупателем Dr.Max, все данные передаются ему, просто получаете скидку.
Купить без всяких промо-кодов, просто сразу со скидкой 50%:
Если какие вопросы — пишите мне по контактам:
Skype: topbase.ru
E-mail: topbase@yandex.ru
Анна


